MDedup: Duplicate Detection with Matching Dependencies
Abstract
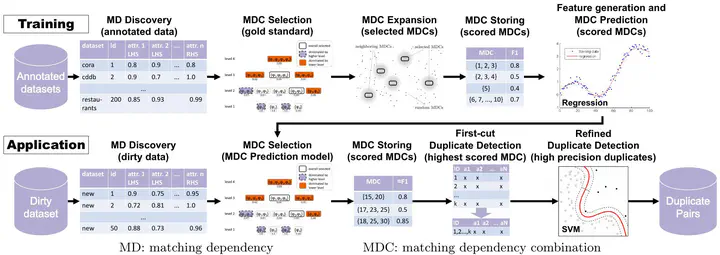
Duplicate detection is an integral part of data cleaning and serves to identify multiple representations of same real-world entities in (relational) datasets. Existing duplicate detection approaches are effective, but they are also hard to parameterize or require a lot of pre-labeled training data. Both parameterization and pre-labeling are at least domain-specific if not dataset-specific, which is a problem if a new dataset needs to be cleaned. For this reason, we propose a novel, rule-based and fully automatic duplicate detection approach that is based on matching dependencies (MDs). Our system uses automatically discovered MDs, various dataset features, and known gold standards to train a model that selects MDs as duplicate detection rules. Once trained, the model can select useful MDs for duplicate detection on any new dataset. To increase the generally low recall of MD-based data cleaning approaches, we propose an additional boosting step. Our experiments show that this approach reaches up to 94% F-measure and 100% precision on our evaluation datasets, which are good numbers considering that the system does not require domain or target data-specific configuration.
Ioannis Koumarelas
PhD graduate in Data Cleaning
My research interests include Data Cleaning, Artificial Intelligence, and Machine Learning.